之前的C++学习都是浅尝辄止,这一次直接购入《C++ Primer Plus》系统深入的学习一些C++的知识,尤其C++擅长的面向对象部分。
引用表在文章末尾
union
union即为联合,它是一种特殊的类。通过关键字union进行定义,一个union可以有多个数据成员。
在任意时刻,联合中只能有一个数据成员可以有值。当给联合中某个成员赋值之后,该联合中的其它成员就变成未定义状态了。
在C/C++程序的编写中,当多个基本数据类型或复合数据结构要占用同一片内存时,我们要使用联合体;当多种类型,多个对象,多个事物只取其一时(我们姑且通俗地称其为“n 选1”),我们也可以使用联合体来发挥其长处。
union主要是共享内存,分配内存以其最大的结构或对象为大小,即sizeof最大的。
1 | union myun |
由于union类型是共享内存,以size最大的结构作为自己的大小,这样的话,myun这个结构就包含u这个结构体,而大小也等于u这个结构体 的大小,在内存中的排列为声明的顺序x,y,z从低到高,然后赋值的时候,在内存中,就是x的位置放置4,y的位置放置5,z的位置放置6,现在对k赋 值,对k的赋值因为是union,要共享内存,所以从union的首地址开始放置,首地址开始的位置其实是x的位置,这样原来内存中x的位置就被k所赋的值代替了,就变为0了,这个时候要进行打印,就直接看内存里就行了,x的位置也就是k的位置是0,而y,z的位置的值没有改变,所以应该是0,5,6。
EasyX的ExMessage的定义就涉及到了union的使用,有兴趣可以看看我写的EasyX的博客。
多文件编译
稍大点的项目一般就不会使用单文件编程。毕竟多文件的好处实在是多,例如模块开发、分工协作、代码复用、结构清晰、方便模块更新。
那么怎么使用C++进行多文件编程呢?最先要搞懂的就是C++程序的文件类型、
文件类型
C++程序常用的文件有两大类
头文件
头文件常常以.h结尾,通常被用于放置各种声明,用于被主程序文件包含
头文件的存在是为了联系多个源文件,是源文件之间的接口。C++与C一样,要求先声明后使用,可是编译的时候是单文件编译的。C++编译过程中C++把每个文件单独编译出来,再通过链接把编译出来的多个文件组成一个可执行程序。编译的时候只检查函数声明,只要该文件能在之前声明过函数就能编译成功。函数定义是在链接阶段检查的,而链接是多文件共同参与的。
但是,每次使用其它文件的函数前都要自己先声明显然很繁琐也容易出错。所以,我们把声明类语句放到一类文件里,称之“头文件”,如果你需要使用到某个函数,就把它所在的头文件包含进来,头文件的内容会在编译前被粘贴到源文件中,这样在编译的时候就能正常通过了。
头文件的内容一般都会使用条件编译预处理语句包住,防止因为依赖关系多次被包含。
1 | //header.h |
既然知道头文件的作用,那哪些东西应该放在头文件?哪些不能放在头文件?很好理解,如果这部分需要复制给每个相关的cpp,就把它放在头文件,如果被多个cpp复制之后,可能导致它们在链接过程出错,就不要放在头文件。 一 一来看:
函数声明:显然应该放在头文件中,前面很清楚。
类定义、结构定义:用函数定义的逻辑想,似乎不能放在头文件中。但它应该放在头文件。第一,每个cpp文件应该有一个定义,在编译的时候编译器才知道怎么为对象分配空间。其次,类型定义不会在内存上分配空间。
模板函数:编译器必须在编译的时候根据函数模板实例化对应的函数,所以应该放在头文件。
内联函数:编译期间被插到调用位置,所以也要放在头文件。
函数定义:不要!C++规定一个程序同签名的函数只能有一个定义。如果你把函数定义放在头文件件,并且同一个程序的多个cpp文件包含了该头文件,这样,在链接的时候会发现多个定义版本,链接报错。
变量定义:不要!与上面类似,被多个文件包含的时候会出现多次定义同一个变量,链接错误。但是,static变量和extern变量可以,以及宏定义的常量,因为这些在多个文件出现并不会出错。
CPP文件
.cpp文件包含模块文件和主程序文件。
主程序文件,顾名思义,就是包含main()函数的文件,是作为程序入口的存在,由它来调用模块文件实现的函数。
模块文件一般存放的是一些函数定义,因此也称为功能模块。
多文件的编译可以一键Build也可以先变异成.o再链接(这种方法会便于模块化更新)
extern变量声明
extern很早就遇到过,但实际用的并不多。
类似于函数的声明和定义,变量也同样可以声明和定义。
引用cnblogs@小人物702的一段话
很多人看了可能糊涂,这里稍微说一下,其实就是变量定义和变量声明的区别,变量定义使用“数据类型+变量名称”的形式,编译器需要给他分配内存单元的;而变量声明使用“extern 变量类型+变量名称”的形式,是告诉编译器我这个变量将在其他外部c文件中定义,我这里只是在外部用它。编译器就不给他分配内存空间,而等到真正遇到变量定义的时候再给他分配内存空间。
由于很多人从开始学C语言就一直把定义变量叫声明变量,一开始就叫错了,所以导致现在分不清定义和声明的区别。要是还理解不了就想想函数的定义和声明,函数定义是编写函数功能实体,编译器要编译这个函数并且要分配内存空间,而函数声明并不生成函数功能实体,只是告诉编译器这是个函数,这个函数在后面将会定义实体,我这里只是提前用,编译器就会接着继续往下编译,如果子函数写在main函数之后,那么声明是必须的,如果不声明函数编译器都不知道这是个函数,编译就会报错。
数据结构
链队列
链式队列,队列的一种形式。
队列,在《大话数据结构》中是这样定义的:
队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
其他
inline内联函数
例如
1 | inline void init(int n) |
优点:
1)inline定义的内联函数,函数代码被放入符号表中,在使用时进行替换(像宏一样展开),效率很高。
2)类的内联函数也是函数。编绎器在调用一个内联函数,首先会检查参数问题,保证调用正确,像对待真正函数一样,消除了隐患及局限性。
3)inline可以作为类的成员函数,刀可以使用所在类的保护成员及私有成员。
缺点:
内联函数以复制为代价,活动产函数开销
1)如果函数的代码较长,使用内联将消耗过多内存
2)如果函数体内有循环,那么执行函数代码时间比调用开销大。
.和->的差异
c++中 . 和 -> 主要是用法上的不同。
1、A.B则A为对象或者结构体;
2、A->B则A为指针,->是成员提取,A->B是提取A中的成员B,A只能是指向类、结构、联合的指针;
例如:
1 | class student |
第一种情况,采用指针访问 student xy,则访问时需要写成 xy.name=”hhhhh”;等价于xy->name=”hhhhh”。
第二种情况,采用普通成员访问 student xy,则访问时需要写成 xy.name=”hhhhh”。
指针传递和引用传递
指针传递在定义形参的时候定义为指针;使用引用传递的话需要在定义形参的时候在变量名前面加一个‘&’。
for(auto i : v)
C++11新特性
范围for,相当于java的for each。v是一个可遍历的容器或流,比如vector类型,i就用来在遍历过程中获得容器里的每一个元素。
1 | vector<int> v={1,2,3,4}; |
结果就是1234
一些常用但是我不会的小细节
string初始化
方式一 :
最简单直接, 直接赋值
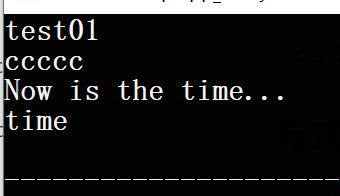
1 | string str1 = "test01" ; |
方式二:
1 | string( size_type length, char ch ); |
以length为长度的ch的拷贝(即length个ch)
1 | string str2( 5, 'c' ); // str2 'ccccc' |
方式三 :
1 | string( const char *str ); |
1 | string str3( "Now is the time..." ); |
方式四:
1 | string( string &str, size_type index, size_type length ); |
以index为索引开始的子串,长度为length, 或者 以从start到end的元素为初值.
1 | string str4( str3, 11, 4 ); //将str3 |
代码示例
1 |
|
引用及致谢(链接指向原文)
union部分:CSDN@W Y
extern部分:cnblogs@小人物702
多文件部分:CSDN@czpcalm
String初始化部分:CSDN@zhangbw~
inline部分:CSDN@tsinfeng